28 Aug 2015
6 mins readOrdered scheduler
Background
The LMAX’s Disruptor is a great piece of software engineering and may be used for many use cases. However as I showed in my previous article on the cost of signalling, multiplying this kind of structure can lead to scheduler contention because we increase the number of threads that may request to the OS scheduler a CPU time slice.
At Ullink we faced this issue for a very concrete case. This case requires keeping ordering while trying to parallelize tasks. In the meantime we would like to reduce the number of threads involved in our application.
Disruptor could resolve our case, but at the price of a consumer thread for each instance. As we may have hundreds of this pattern for a running application, we will increase significantly the number of threads and therefore the pressure on the scheduler.
Georges Gomes, CTO of Ullink, find out in an intel’s article an alternative approach for solving our problem. This article talks about the following issue: How to parallelize some tasks and keeping ordering in the mean time?
Here is an example: we have a video stream and we want to re-encode it. We read from the input stream each frame and we re-encode it before writing it into an output stream. Clearly, frame encoding can be parallelized. Each frame is an independent source of data. The problem is we need to keep ordering of the frames otherwise the video stream would not have any sense!
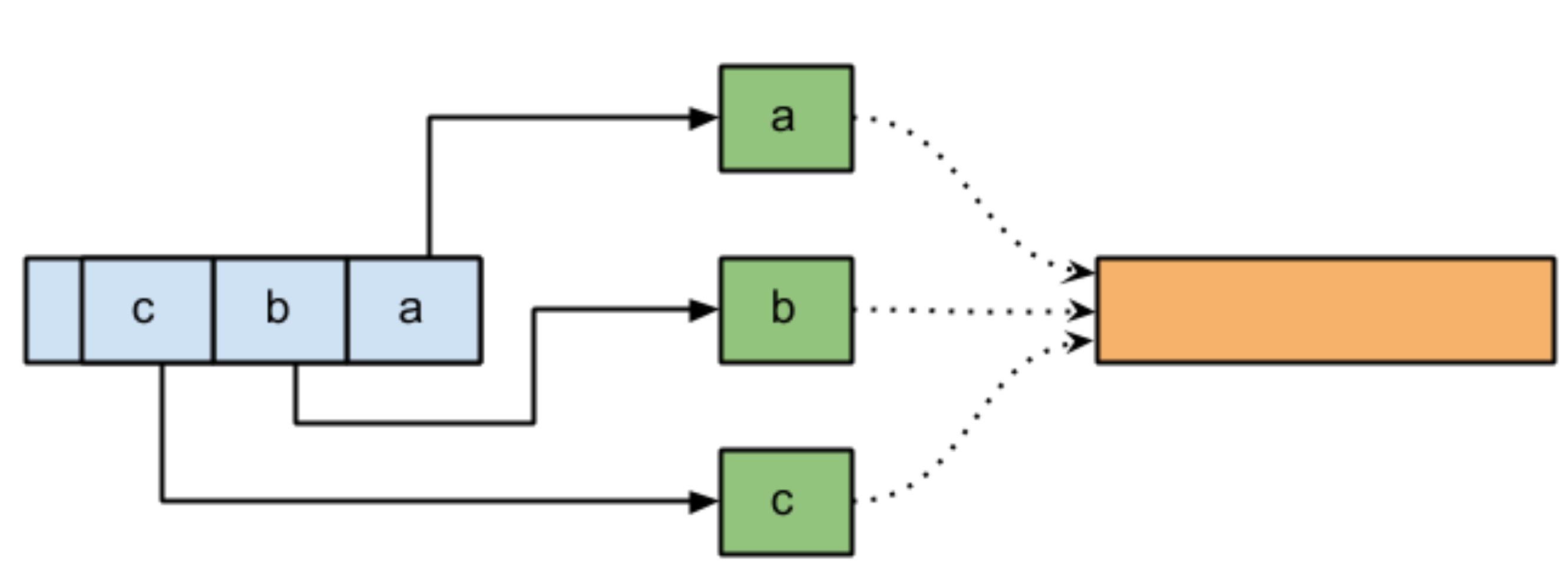
To solve this problem, we need to use an order buffer:
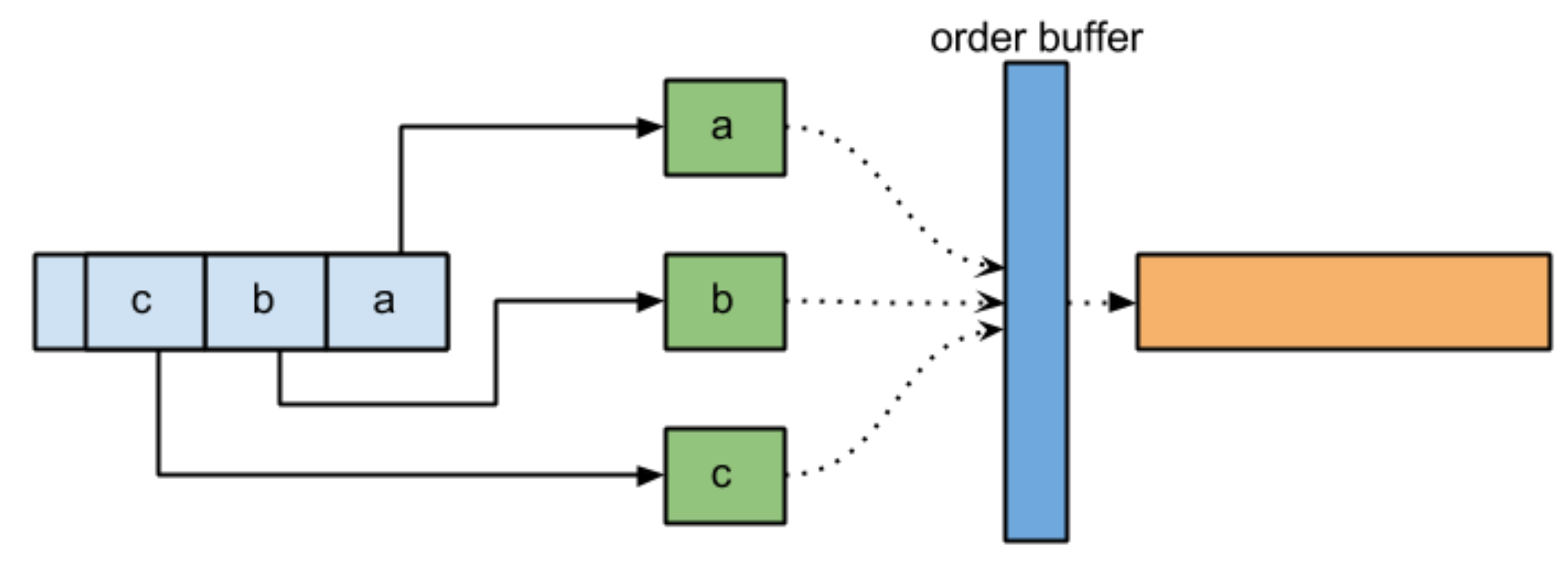
This buffer keeps items until the proper order is respected then write into the output stream. To ensure the proper ordering, each task will grab a ticket on which the algorithm will order the processing.
Each thread is responsible to execute the algorithm and make sure it is its turn to write into the output stream or not. If not, it leaves the item into the order buffer and this is the threads of the previous items (in order) to take care of item leftover. It means we do not have a dedicated consumer thread. It leads us to the following advantages:
- No inter-thread communication overhead (signalling: wait/notify, await/signal)
- No additional thread
- No wait strategy (spining, back-off, …)
We can then multiply this kind of structure without the fear to increase significantly the number of threads running in the application. Bonus: we reduce the need for synchronization that was previously required to ensure ordering.
Algorithm
When tasks are created/dispatched we need to keep track of the order in which they were by assigning a ticket to it. This ticket is just a sequence that we keep incrementing. For the order buffer we will create an ring buffer style structure with tail counter.
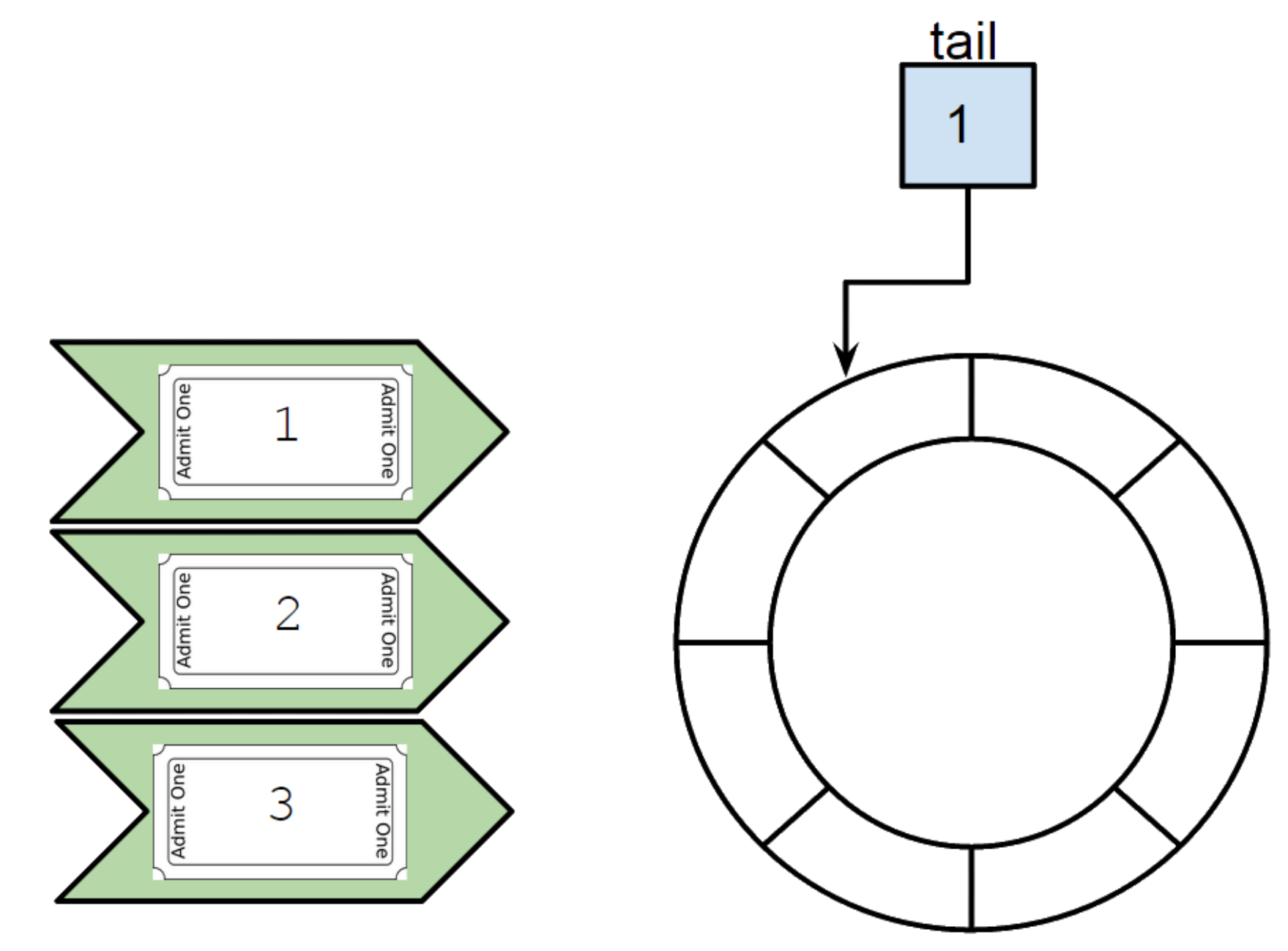
When one of the task entered into the structure, we check if its ticket number matches with the tail counter. If it matches we process the task with the current thread entering and we increment tail.
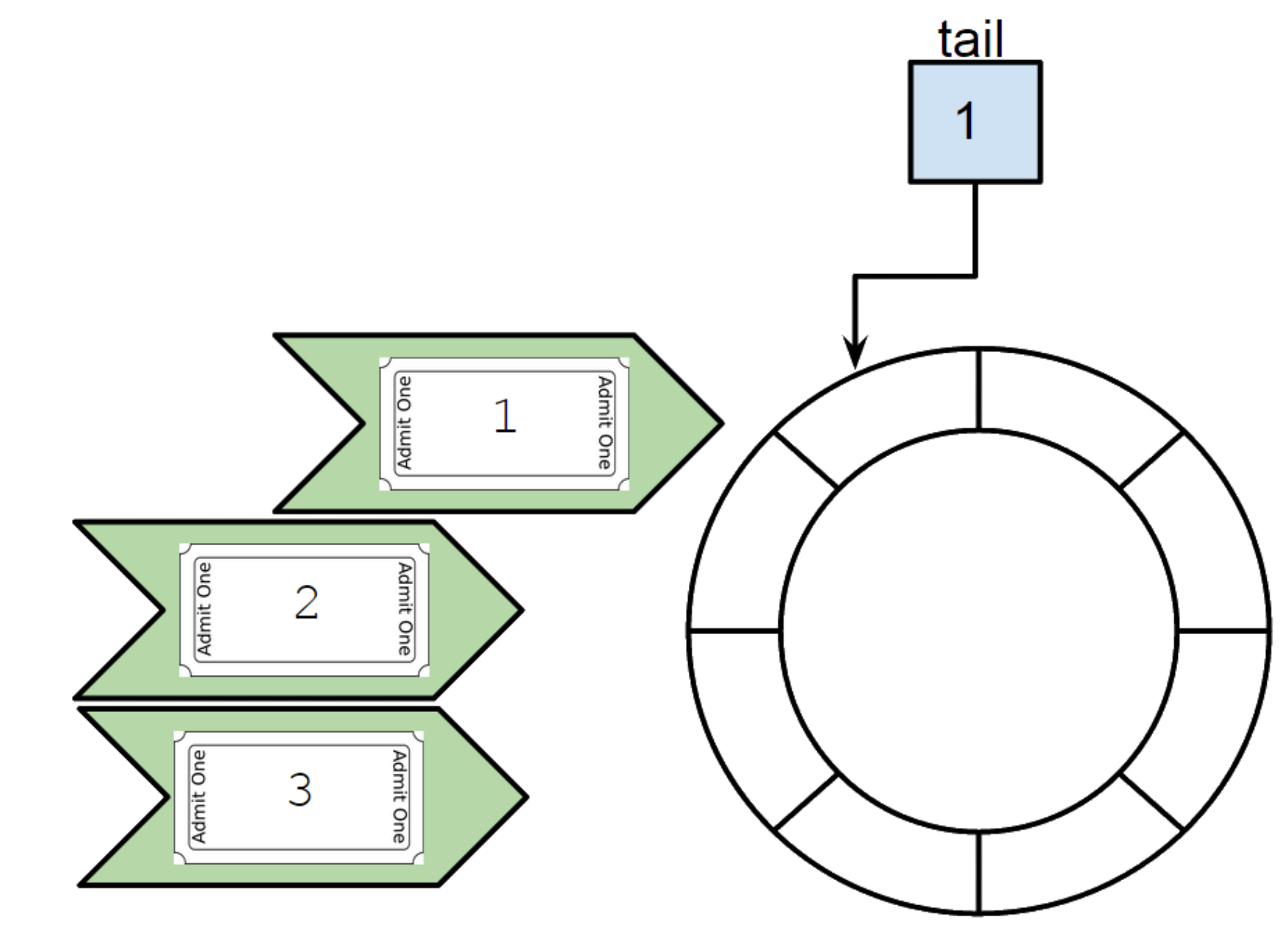
Next, this is the thread containing the ticket number 3 which (by the game of scheduling) comes. Here the ticket number does not match with current tail (2).
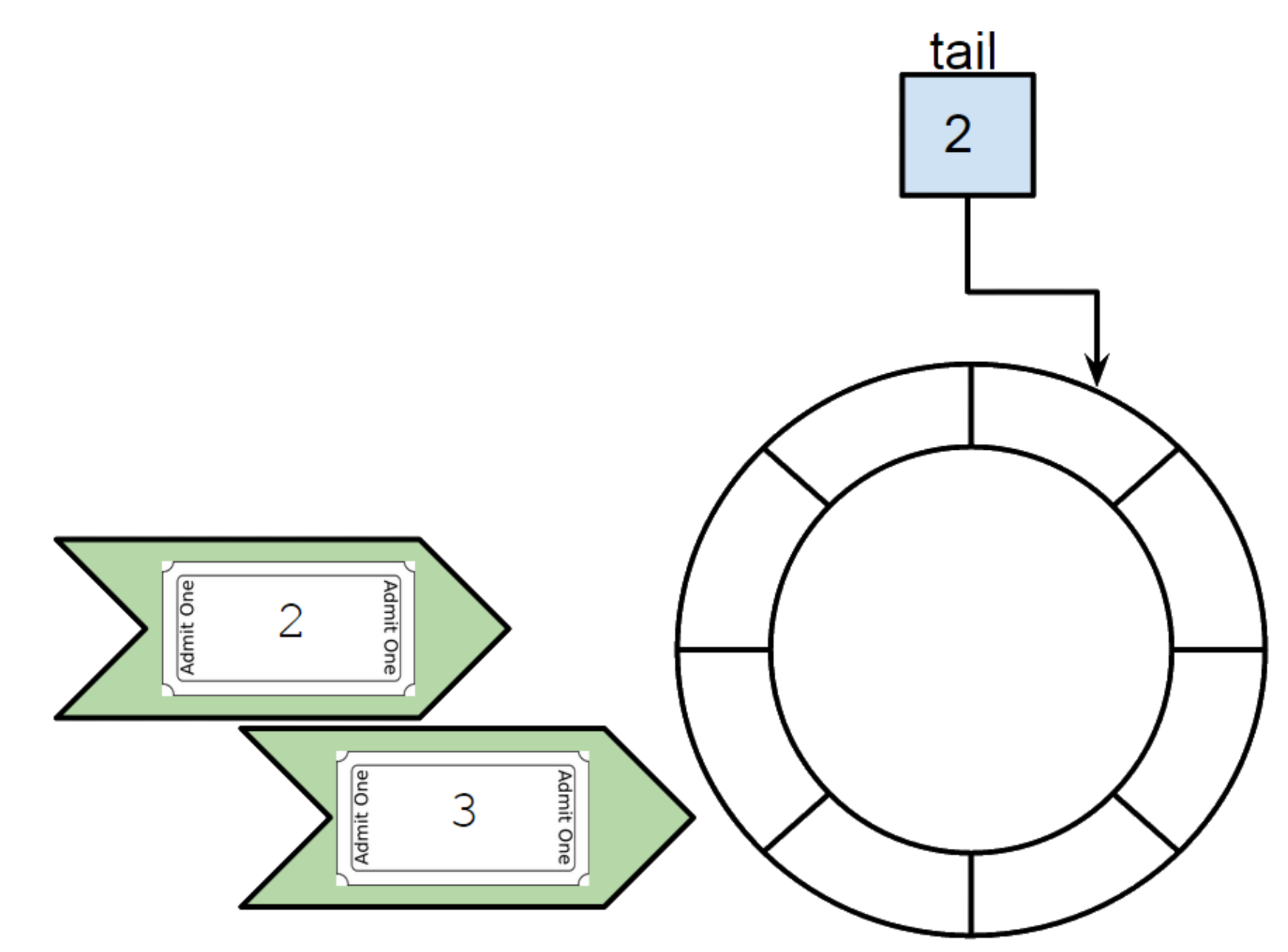
We then put at ticket number index (modulo the length of the ring buffer) the task we would like to process into the ring buffer. And we let the thread free to go.
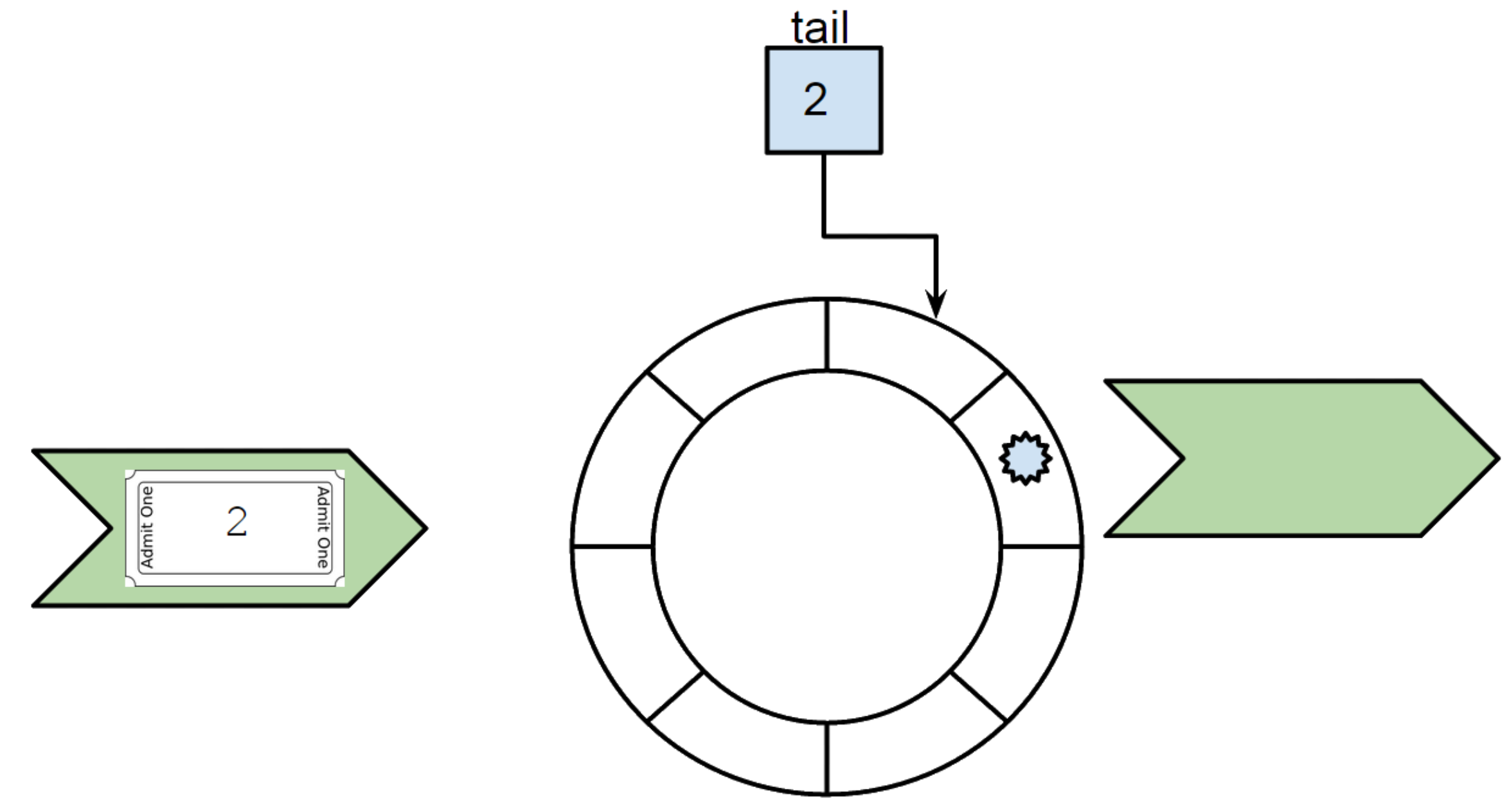
Finally, the thread with ticket number 2 comes. It matches the tail so we can process the task immediately and increment the tail.
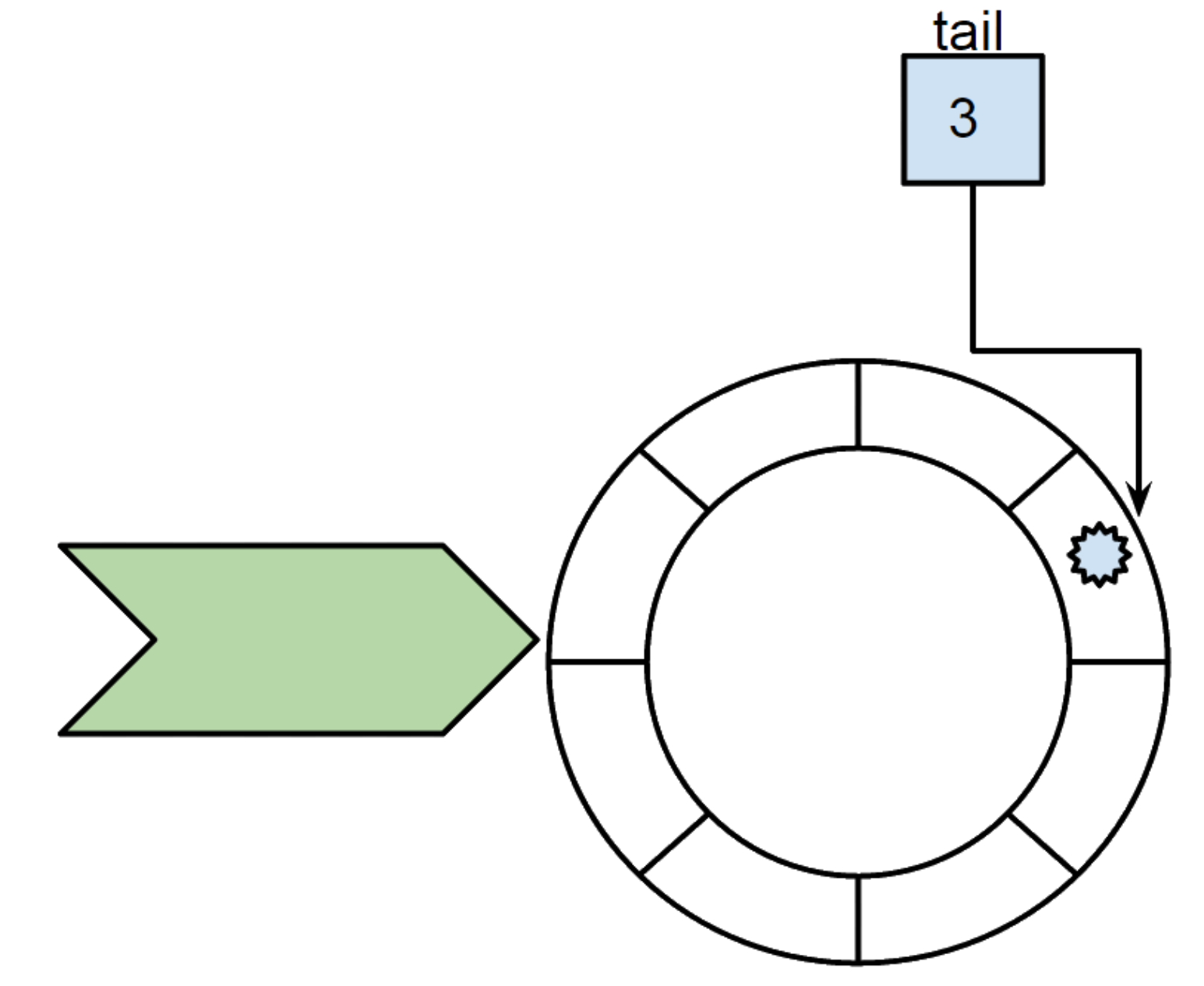
We examine if there is still tasks at the next index from the tail. There is the task with ticket number 3 that was left by previous thread, so it is its turn so we reused the current thread to execute the task.
And we’re done!
Ordered Scheduler
If you have a code like this:
// called by multiple threads (e.g. thread pool)
public void execute()
{
synchronized (this)
{
// this call needs to be synchronized along the write() to guarantee same ordering
FooInput input = read();
// this call is therefore not executed conccurently (#1)
BarOutput output = process(input);
// both write calls need to done in the same order as the read(),
// forcing them to be under the same lock
write(output);
}
}
You need to synchronized to ensure your code is keeping the ordering required when writing to the output. With Ordered Scheduler you can change your code to:
OrderedScheduler scheduler = new OrderedScheduler()
public void execute()
{
long ticket;
FooInput input;
synchronized (this)
{
input = read();
// read() is successful. No exceptions. Let's take the ticket.
// ticket will "record" the ordering of read() calls, and use it to guarantee same write() ordering
ticket = getNextTicket();
}
try
{
// this will be executed concurrently (obviously needs to be thread-safe)
BarOutput output = process(input);
}
catch(Exception e)
{
// Important to trash the ticket in case of a problem during the processing
// otherwise scheduler.run() will wait infinitely
scheduler.trash(ticket);
throw new RuntimeException(e);
}
// Let run the write() in the ticket order
scheduler.run(ticket, () => { write(output); } );
}
Synchronized block is still required in this example to ensure the input is attached to right ticket. You could do differently by reading your input into a single thread, taking the ticket and then dispatch into a thread pool your process tasks. Your call to the ordered scheduler will then serialize your output.
What is important to keep in mind is that you cannot miss a ticket. This is why in this example is an exception is thrown during the process we call the trash method to inform the ordered scheduler that ticket is no longer valid, otherwise it would wait for ever that ticket to come into the scheduler.
The implementation is open sourced on GitHub.