24 Oct 2012
17 mins readVirtual Call 911
Since we know now how to print JIT code & how far JIT compiler can optimize byte code, let’s dig how it can optimize the most common use case in Java : a virtual call.
What is a Virtual Call?
A classic call is just a jump to a specific address where the code of the method resides independently of the class of the object.
A virtual call is more complex: the method to be called is dependent of the class of the object. Each class can have a specific implementation of the method. So the compiler cannot resolve at compile time which implementation it should call. The resolution is based on the underlying class of an instance.
Traditional object oriented languages implement virtual call by putting in each instance of class a pointer to the Virtual Method Table (VMT) which contain all virtual methods defined in the class.
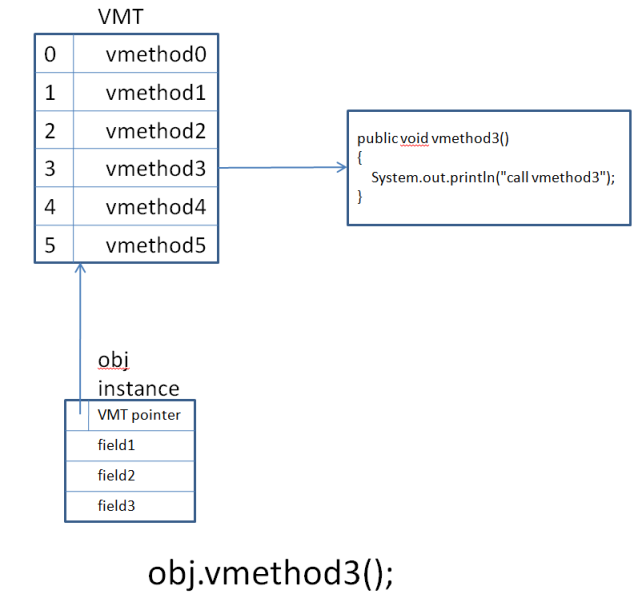
So a virtual call needs to:
- Load the instance
- Follow the link to the VMT
- Jump to the address corresponding of the VMT entry.
For an inherited class, usually, a new VMT is created with inherited methods. For an overridden method, the VMT entry is replaced by the overridden implementation.
Virtual call in Java
Some OO languages like C++, C#, Delphi (yeah, I have some legacy with this language…) mix classic and virtual methods by marking them with modifiers like virtual & override keywords. However, in Java, there is no such modifiers, so all methods are virtual by default. Of course except static, private and constructor ones.
Considering what each virtual call implies, we can expect non negligible overhead for each call! How the JIT can help on this situation?
Final
The old fashion way to optimize this kind of calls is to mark methods as final. JIT Compiler is informed that no other classes will extend this class in the future so no other overridden implementation is expected.
Let’s verify that with this example:
package com.bempel.sandbox;
public class TestJIT
{
public static void main(String[] args) throws Exception
{
MyClass obj = new MyClass();
for (int i = 0; i < 10000; i++)
{
benchVMethod(obj);
}
Thread.sleep(1000);
}
public static void benchVMethod(MyClass obj)
{
obj.vmethod();
}
private static class MyClass
{
public final void vmethod()
{
if (System.currentTimeMillis() == 0)
{
System.out.println("call to vmethod");
}
}
}
}
Executed with JVM arguments:
-server -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -XX:-Inline
We get:
[Entry Point]
[Disassembling for mach='i386']
[Verified Entry Point]
# {method} 'benchVMethod' '(Lcom/bempel/sandbox/TestJIT$MyClass;)V' in 'com/bempel/sandbox/TestJIT'
# parm0: ecx = 'com/bempel/sandbox/TestJIT$MyClass'
# [sp+0x10] (sp of caller)
0x02488fc0: mov %eax,-0x3000(%esp)
0x02488fc7: push %ebp
0x02488fc8: sub $0x8,%esp ;*synchronization entry
; - com.bempel.sandbox.TestJIT::benchVMethod@-1 (line 17)
0x02488fce: test %ecx,%ecx
0x02488fd0: je 0x02488fe3
0x02488fd2: nop
0x02488fd3: call 0x0246d040 ; OopMap{off=24}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 17)
; {optimized virtual_call}
0x02488fd8: add $0x8,%esp
0x02488fdb: pop %ebp
0x02488fdc: test %eax,0x110000 ; {poll_return}
0x02488fe2: ret
Note: I have used -XX:-Inline to avoid confusion in reading disassembly with inline optimization.
As you can see our invokevirtual to vmethod was translated by an "optimized virtual_call" to a specific address, so a classic call.
To be sure we have an optimized virtual call, let’s re-activate the inline optimizations:
[Disassembling for mach='i386']
[Entry Point]
[Verified Entry Point]
# {method} 'benchVMethod' '(Lcom/bempel/sandbox/TestJIT$MyClass;)V' in 'com/bempel/sandbox/TestJIT'
# parm0: ecx = 'com/bempel/sandbox/TestJIT$MyClass'
# [sp+0x10] (sp of caller)
0x02468000: mov %eax,-0x3000(%esp)
0x02468007: push %ebp
0x02468008: sub $0x8,%esp ;*synchronization entry
; - com.bempel.sandbox.TestJIT::benchVMethod@-1 (line 25)
0x0246800e: test %ecx,%ecx
0x02468010: je 0x02468028 ;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 25)
0x02468012: call 0x6ddfe3a0 ;*invokestatic currentTimeMillis
; - com.bempel.sandbox.TestJIT$MyClass::vmethod@0 (line 32)
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 25)
; {runtime_call}
0x02468017: mov %eax,%ebx
0x02468019: or %edx,%ebx
0x0246801b: je 0x02468035 ;*ifne
; - com.bempel.sandbox.TestJIT$MyClass::vmethod@5 (line 32)
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 25)
0x0246801d: add $0x8,%esp
0x02468020: pop %ebp
0x02468021: test %eax,0x110000 ; {poll_return}
0x02468027: ret
You can see a call the System.currentTimeMillis in benchVMethod, so, effectively, the vmethod was inlined into benchVMethod. Inlining cannot be perform with regular virtual calls but only on classic calls.
What about removing final modifier? Well the result is strictly the same! Of course, we have only one class and no hierarchy, so let’s add more classes:
package com.bempel.sandbox;
public class TestJIT
{
public static void main(String[] args) throws Exception
{
MyClass obj = new MyClass();
MyClass obj2 = new MyClass2();
MyClass obj3 = new MyClass3();
MyClass obj4 = new MyClass4();
MyClass obj5 = new MyClass5();
for (int i = 0; i < 10000; i++)
{
benchVMethod(obj);
benchVMethod(obj2);
benchVMethod(obj3);
benchVMethod(obj4);
benchVMethod(obj5);
}
Thread.sleep(1000);
}
public static void benchVMethod(MyClass obj)
{
obj.vmethod();
}
private static class MyClass
{
public void vmethod()
{
if (System.currentTimeMillis() == 0)
{
System.out.println("call to MyClass.vmethod");
}
}
}
private static class MyClass2 extends MyClass
{
@Override
public void vmethod()
{
if (System.currentTimeMillis() == 0)
{
System.out.println("call to MyClass2.vmethod");
}
}
}
private static class MyClass3 extends MyClass
{
@Override
public void vmethod()
{
if (System.currentTimeMillis() == 0)
{
System.out.println("call to MyClass3.vmethod");
}
}
}
private static class MyClass4 extends MyClass
{
@Override
public void vmethod()
{
if (System.currentTimeMillis() == 0)
{
System.out.println("call to MyClass4.vmethod");
}
}
}
private static class MyClass5 extends MyClass
{
@Override
public void vmethod()
{
if (System.currentTimeMillis() == 0)
{
System.out.println("call to MyClass5.vmethod");
}
}
}
}
[Disassembling for mach='i386']
[Entry Point]
[Verified Entry Point]
# {method} 'benchVMethod' '(Lcom/bempel/sandbox/TestJIT$MyClass;)V' in 'com/bempel/sandbox/TestJIT'
# parm0: ecx = 'com/bempel/sandbox/TestJIT$MyClass'
# [sp+0x10] (sp of caller)
0x023f8a80: mov %eax,-0x3000(%esp)
0x023f8a87: push %ebp
0x023f8a88: sub $0x8,%esp
0x023f8a8e: mov $0xffffffff,%eax ; {oop(NULL)}
0x023f8a93: call 0x023dd240 ; OopMap{off=24}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 25)
; {virtual_call}
0x023f8a98: add $0x8,%esp
0x023f8a9b: pop %ebp
0x023f8a9c: test %eax,0x180000 ; {poll_return}
0x023f8aa2: ret ;*invokevirtual vmethod
Even with inline optimization on, we have the same result. However there is still a call to a specific address, so I suspect here there is stub before real VMT resolution. We need to rely on comments and inlining to verify virtual call optimizations.
Class Hierarchy Analysis
However reducing the number of classes overriding vmethod to 2 will give us an optimized virtual call (again here without inlining):
[Disassembling for mach='i386']
[Entry Point]
[Verified Entry Point]
# {method} 'benchVMethod' '(Lcom/bempel/sandbox/TestJIT$MyClass;)V' in 'com/bempel/sandbox/TestJIT'
# parm0: ecx = 'com/bempel/sandbox/TestJIT$MyClass'
# [sp+0x10] (sp of caller)
0x026b7fe0: mov %eax,-0x3000(%esp)
0x026b7fe7: push %ebp
0x026b7fe8: sub $0x8,%esp ;*synchronization entry
; - com.bempel.sandbox.TestJIT::benchVMethod@-1 (line 19)
0x026b7fee: mov 0x4(%ecx),%ebx ; implicit exception: dispatches to 0x026b8038
0x026b7ff1: cmp $0x581d158,%ebx ; {oop('com/bempel/sandbox/TestJIT$MyClass2')}
0x026b7ff7: je 0x026b800a
0x026b7ff9: cmp $0x581cc18,%ebx ; {oop('com/bempel/sandbox/TestJIT$MyClass')}
0x026b7fff: jne 0x026b801b
0x026b8001: xchg %ax,%ax
0x026b8003: call 0x0269d040 ; OopMap{off=40}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 19)
; {optimized virtual_call}
0x026b8008: jmp 0x026b8010
0x026b800a: nop
0x026b800b: call 0x0269d040 ; OopMap{off=48}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 19)
; {optimized virtual_call}
0x026b8010: add $0x8,%esp
0x026b8013: pop %ebp
0x026b8014: test %eax,0x180000 ; {poll_return}
0x026b801a: ret
0x026b801b: mov %ecx,%ebp
0x026b801d: mov $0xffffffc6,%ecx
0x026b8022: nop
0x026b8023: call 0x0269c700 ; OopMap{ebp=Oop off=72}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 19)
; {runtime_call}
0x026b8028: int3
0x026b8029: mov %eax,%ecx
0x026b802b: jmp 0x026b802f
0x026b802d: mov %eax,%ecx
0x026b802f: add $0x8,%esp
0x026b8032: pop %ebp
0x026b8033: jmp 0x026b86c0 ; {runtime_call}
0x026b8038: mov $0xfffffff6,%ecx
0x026b803d: xchg %ax,%ax
0x026b803f: call 0x0269c700 ; OopMap{off=100}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 19)
; {runtime_call}
0x026b8044: int3 ;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 19)
What is interesting in here is we have multiple optimized calls. Before these, we have tested against classes, so the type of the instance is compared to see if this is MyClass or MyClass2 depending on that, we call the method accordingly. We can see that the address is the same. However the comment says OopMap{off=40} or OopMap{off=48} so we can assume that this is a stub to dispatch to the real method.
This is what we call a bimorhpic call. Monomorphic call is the first one with only one class. Virtual calls without class test is a megamorphic call.
Since we have 2 classes involved here and based on the analysis of the class hierarchy, JIT compiler is able to optimize the virtual call as a special case between 2 classes with just a test on the type.
Profiling
Another remark with the previous example: If the class is not one of the test, we fallback to virtual call but there is a int 3 instruction just after. This instruction is used as a trap by JIT compiler to trigger a deoptimization. JIT compiler tries to perform optimitic optimization. During interpretation phase, JVM collects statistics about execution and calls. When number of calls of a method reaches the CompileThreshold, the JIT compiler kicks in and produced native code with optimization based on the statistics gathered. So if we have only executed calls with one or two types, virtual calls are optimized consequently. But if another class is now involved, optimizations are no longer relevant. The JIT compiler deoptimizes the previous code and produced another native code usually with less aggressive optimization, based on the new information.
So let’s verify it: we have modified the code to warmup with only one type for the call but there is 2 classes used during the execution:
public static void main(String[] args) throws Exception
{
MyClass obj = new MyClass();
MyClass obj2 = new MyClass2();
for (int i = 0; i < 10000; i++)
{
benchVMethod(obj);
}
Thread.sleep(1000);
for (int i = 0; i < 10000; i++)
{
benchVMethod(obj2);
}
Thread.sleep(1000);
}
When executed with only these options: -server -XX:+PrintCompilation
We see:
--- n java.lang.System::currentTimeMillis (static)
1 com.bempel.sandbox.TestJIT::benchVMethod (5 bytes)
2 com.bempel.sandbox.TestJIT$MyClass::vmethod (17 bytes)
1 made not entrant (2) com.bempel.sandbox.TestJIT::benchVMethod (5 bytes)
3 com.bempel.sandbox.TestJIT::benchVMethod (5 bytes)
4 com.bempel.sandbox.TestJIT$MyClass2::vmethod (17 bytes)
benchVMethod is compiled once (index 1) and then made not entrant means deoptimized. JIT recompiled it (index 6). With -XX:+PrintAssembly we can now see 2 versions of benchVMethod:
[Disassembling for mach='i386']
[Entry Point]
[Verified Entry Point]
# {method} 'benchVMethod' '(Lcom/bempel/sandbox/TestJIT$MyClass;)V' in 'com/bempel/sandbox/TestJIT'
# parm0: ecx = 'com/bempel/sandbox/TestJIT$MyClass'
# [sp+0x10] (sp of caller)
0x024b8d00: mov %eax,-0x3000(%esp)
0x024b8d07: push %ebp
0x024b8d08: sub $0x8,%esp ;*synchronization entry
; - com.bempel.sandbox.TestJIT::benchVMethod@-1 (line 23)
0x024b8d0e: mov 0x4(%ecx),%ebx ; implicit exception: dispatches to 0x024b8d44
0x024b8d11: cmp $0x56dcc38,%ebx ; {oop('com/bempel/sandbox/TestJIT$MyClass')}
0x024b8d17: jne 0x024b8d2b
0x024b8d19: xchg %ax,%ax
0x024b8d1b: call 0x0249d040 ; OopMap{off=32}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 23)
; {optimized virtual_call}
0x024b8d20: add $0x8,%esp
0x024b8d23: pop %ebp
0x024b8d24: test %eax,0x180000 ; {poll_return}
0x024b8d2a: ret
[Disassembling for mach='i386']
[Entry Point]
[Verified Entry Point]
# {method} 'benchVMethod' '(Lcom/bempel/sandbox/TestJIT$MyClass;)V' in 'com/bempel/sandbox/TestJIT'
# parm0: ecx = 'com/bempel/sandbox/TestJIT$MyClass'
# [sp+0x10] (sp of caller)
0x024b8f60: mov %eax,-0x3000(%esp)
0x024b8f67: push %ebp
0x024b8f68: sub $0x8,%esp ;*synchronization entry
; - com.bempel.sandbox.TestJIT::benchVMethod@-1 (line 23)
0x024b8f6e: mov 0x4(%ecx),%ebx ; implicit exception: dispatches to 0x024b8fb8
0x024b8f71: cmp $0x56dcc38,%ebx ; {oop('com/bempel/sandbox/TestJIT$MyClass')}
0x024b8f77: je 0x024b8f8a
0x024b8f79: cmp $0x56dd178,%ebx ; {oop('com/bempel/sandbox/TestJIT$MyClass2')}
0x024b8f7f: jne 0x024b8f9b
0x024b8f81: xchg %ax,%ax
0x024b8f83: call 0x0249d040 ; OopMap{off=40}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 23)
; {optimized virtual_call}
0x024b8f88: jmp 0x024b8f90
0x024b8f8a: nop
0x024b8f8b: call 0x0249d040 ; OopMap{off=48}
;*invokevirtual vmethod
; - com.bempel.sandbox.TestJIT::benchVMethod@1 (line 23)
; {optimized virtual_call}
0x024b8f90: add $0x8,%esp
0x024b8f93: pop %ebp
0x024b8f94: test %eax,0x180000 ; {poll_return}
0x024b8f9a: ret
So first one, we have only one test against one class. Second one, 2 tests for 2 classes. This is why it is so important to execute all code paths during warmup to give to JIT compiler all informations required to be able to compile correctly on the first time.
We can also remark here that since there is 2 classes loaded, the first version, has a test on the class that is executed unlike on our first test with only one class loaded, there was no test against class since there is no class inherited (class hierarchy analysis).
Interfaces
What about interfaces? Byte code instruction is invokeinterface instead of invokevirtual, Is it really different?
Let’s verify it with a classic List:
package com.bempel.sandbox;
import java.util.ArrayList;
import java.util.List;
public class TestJIT
{
private static void call(List<string> list)
{
list.add("foo");
}
public static void main(String[] args) throws Exception
{
List<string>[] lists = new List[] { new ArrayList<string>()};
for (int i = 0; i < 10000; i++)
call(lists[i % lists.length]);
Thread.sleep(1000);
}
}
Disassembly code:
[Disassembling for mach='i386']
[Entry Point]
[Verified Entry Point]
# {method} 'call' '(Ljava/util/List;)V' in 'com/bempel/sandbox/TestJIT'
# parm0: ecx = 'java/util/List'
# [sp+0x10] (sp of caller)
0x024c9080: mov %eax,-0x3000(%esp)
0x024c9087: push %ebp
0x024c9088: sub $0x8,%esp ;*synchronization entry
; - com.bempel.sandbox.TestJIT::call@-1 (line 10)
0x024c908e: mov 0x4(%ecx),%ebp ; implicit exception: dispatches to 0x024c90c8
0x024c9091: cmp $0x568f6a0,%ebp ; {oop('java/util/ArrayList')}
0x024c9097: jne 0x024c90af
0x024c9099: mov $0x56ecb40,%edx ; {oop("foo")}
0x024c909e: nop
0x024c909f: call 0x024ad040 ; OopMap{off=36}
;*invokeinterface add
; - com.bempel.sandbox.TestJIT::call@3 (line 10)
; {optimized virtual_call}
0x024c90a4: add $0x8,%esp
0x024c90a7: pop %ebp
0x024c90a8: test %eax,0x110000 ; {poll_return}
0x024c90ae: ret
It looks like very similar with invokevirtual. Since there are multiple implementations of List loaded into the JVM there is a test against ArrayList class. Let’s add another class in our test:
package com.bempel.sandbox;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
public class TestJIT
{
private static void call(List<string> list)
{
list.add("foo");
}
public static void main(String[] args) throws Exception
{
List<string>[] lists = new List[] { new ArrayList<string>(), new CopyOnWriteArrayList<string>()};
for (int i = 0; i < 12000; i++)
call(lists[i % lists.length]);
Thread.sleep(1000);
}
}
Note: I do not know yet why we need to increase to 12000 calls to get call method compiled…
And now the disassembly code:
[Disassembling for mach='i386']
[Entry Point]
[Verified Entry Point]
# {method} 'call' '(Ljava/util/List;)V' in 'com/bempel/sandbox/TestJIT'
# parm0: ecx = 'java/util/List'
# [sp+0x10] (sp of caller)
0x02507fe0: mov %eax,-0x3000(%esp)
0x02507fe7: push %ebp
0x02507fe8: sub $0x8,%esp ;*synchronization entry
; - com.bempel.sandbox.TestJIT::call@-1 (line 11)
0x02507fee: mov 0x4(%ecx),%ebx ; implicit exception: dispatches to 0x0250803c
0x02507ff1: mov $0x5730520,%edx ; {oop("foo")}
0x02507ff6: cmp $0x572fe18,%ebx ; {oop('java/util/concurrent/CopyOnWriteArrayList')}
0x02507ffc: je 0x0250800e
0x02507ffe: cmp $0x56cf6a0,%ebx ; {oop('java/util/ArrayList')}
0x02508004: jne 0x0250801f
0x02508006: nop
0x02508007: call 0x024ed040 ; OopMap{off=44}
;*invokeinterface add
; - com.bempel.sandbox.TestJIT::call@3 (line 11)
; {optimized virtual_call}
0x0250800c: jmp 0x02508014
0x0250800e: nop
0x0250800f: call 0x024ed040 ; OopMap{off=52}
;*invokeinterface add
; - com.bempel.sandbox.TestJIT::call@3 (line 11)
; {optimized virtual_call}
0x02508014: add $0x8,%esp
0x02508017: pop %ebp
0x02508018: test %eax,0x180000 ; {poll_return}
0x0250801e: ret
See? A bimorphic call on add method with 2 tests against CopyOnWriteArrayList and ArrayList classes.
Conclusion
We have demonstrated here that abstraction does not slow you down! You can use your interfaces or abstract classes to call your methods without any doubt about performance. So, use List or Map interfaces instead of concrete types for variable/field, JIT compiler will optimize it for you.
Also getters and setters of object will be largely optimized by monomorphic call followed by inlining !
Finally, final keyword is no longer required to help JIT compiler, so let’s remove it since it prevents you to override method in some cases!